虚拟歌姬(歌声合成软件)
此页面内的部分配图为编写者本人文件,切勿二次使用
简介
歌声合成技术是一种利用计算机算法和数字信号处理技术,将人声、乐器等音频信号进行分析、处理和合成,生成与人类声音类似的音频信号的技术。 它可以模拟人类的歌唱声音,实现人工合成歌声,并且可以根据设定的旋律和歌词进行自动合成。
- 此外,“虚拟歌姬”词条虽然归类在词条“VOCALOID”之下,但并不是所有的虚拟歌姬都来自于VOCALOID,即“ボカロ” “术力口”。虽然我们经常将采用了虚拟歌姬的曲子称为“术力口曲”/“术曲”,但有时不同的歌姬对应了不同的公司。不过目前“术力口”一词已经广义地涵盖了大多数的歌声合成虚拟歌姬,我们也可以将这一类曲子统称为术曲,这并不是原则性的问题。
历史发展
初代 VOCALOID(2003年)
2003年3月5日,日本公司Yamaha在德国法兰克福乐器展上公开了一款拥有“歌声合成”功能的名叫“VOCALOID”的程序。
跨时代的虚拟歌姬 初音未来(2007年)
2007年8月31日,由Crypton Future Media以雅马哈的Vocaloid系列语音合成程序为基础开发的音源库(cv:藤田咲)。
初始之音,响彻未来
人人都可以自制声库 UTAU(2008年)
一款由饴屋/菖蒲(饴屋P)开发制作的免费闭源歌声合成软件,在最初是为了辅助人力VOCALOID制作而制作的软件。
2008年03月06日发布时最初的名字为:炉利音声音编辑软件(Loliedit),后于3月15日改为现名,名字来源于日语“歌う”(歌唱)。
中文 VOCALOID(2012年)
在2011年7月16日,中文V3初次提出概念。
而在2012年1月17日,征集结果公布:雅音宫羽(by MOTH)、绫彩音(by ハオ)、牙音(by aya)、MOKO(by再音saku)、蝶音(byHANS)。
随后同年3月22日,VOCALOID CHINA PROJECT官方形象公布:雅音宫羽→洛天依、绫彩音→乐正绫、牙音→乐正龙牙、MOKO→徵羽摩柯、墨清弦。6月,洛天依信息正式发布。
华风夏韵,洛水天依
新生代歌声合成的领跑者 Synthesizer V(2018年)
主流歌声合成软件
VOCALOID
UTAU
Synthesizer V
Synthesizer V(简称 Synth V 或 SV)是由以华侃如(Kanru Hua)为首的 Dreamtonics Co,. Ltd.开发的歌声合成引擎及编辑器软件(V表示第5次架构迭代)。该引擎采用了自主研发的基于人工神经网络及拼接合成算法的 LLSM(底层语音模型)技术,仅使用少量采样数据即能生成自然的声音。
- Synthesizer V AI 和 Synthesizer V Standard (Std) 是属于两个版本的歌声数据库。部分歌姬属于AI(使用了DNN深度学习技术),而Std则是融合人工神经网络(ANN)和样本的全新歌声合成引擎。
PaintVoice
一款在手机上的歌声合成软件
CeVIO
CeVIO的诞生源自于创作者团体,也就是V-Sync和Frontier Works这两家公司共同开发,技术方面主要是Techno-speech来担任。而Techno-speech是进行着最前端的TTS研究的名古屋工业大学内的创业公司。
CeVIO AI 搭载了CeVIO项目开发的歌声和语音合成技术,可以利用最新的AI技术以前所未有的准确度再现人类的语音质量、习惯、唱歌和说话,是一款全新的声音创作软件。 CeVIO AI不仅可以真实地再现人类的歌声和说话的声音,而且具有易于使用的图形界面,可以自由编辑音高、发音时长等,为声音创作开辟新的可能性。
Voisona
VoiSona作为一款能够真实再现人类歌声的 AI 歌唱软件,其名称是由“Voice”(声音)和“Persona”(人格、魅力)结合而成,蕴含着通过声音展现多样个性的理念。该软件以テクノスピーチ多年积累的 AI 技术为基础,实现了 Windows/macOS 双系统兼容,以及 VSTi/Audio Units 对应等功能,使其更加易用,能够满足专业需求。软件默认附带具有中性魅力声音的日语歌手「知声」,同时还包含简易的独立应用程序,即使没有 VSTi/Audio Units 对应的 DAW,用户也可以使用。使用「VoiSona」和「知声」输出的语音波形数据,在个人/法人、商用/非商用的情况下,除部分例外情况外,原则上可以免费使用。
Voisona与CeVio曾属于同源。Techno-Speech公司为了追求突破CeVio的框架的限制,独立开发了Voisona来追寻更多的可能性。不同的是CeVio的工程保存文件为css,而Voisona的工程保存文件为tssln。
让我们来了解一下歌唱的原理吧
TTS,VC,SVS
TTS是Text to speech的略称,就是音声合成(或语音合成)。
我们在上文说到的VOCALOID,UTAU,CeVIO AI都是TTS的一种。像VOICEROID这样的语音特化的音源也被称作是TTS。
VC是Voice conversion的简称,也就是文本转语音。保留文本的内容,而对语音进行替换,
SVS是Singing voice synthesis的简称,也就是歌声合成。据歌词和乐谱信息合成歌唱。相比于TTS使机器“开口说话”,歌唱合成则是让机器唱歌。
我们可以通过最近的浙江大学,北京大学和腾讯AI实验室(Tencent AI Lab)的一则文献来大概了解一下原理
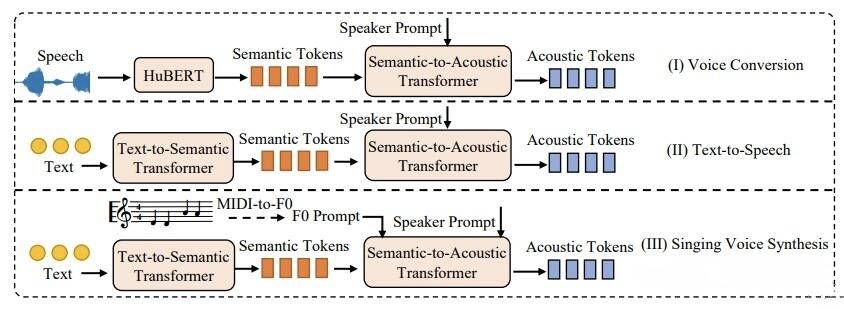

顺带一提,虽然目前市面上大多数的编辑软件的原理都是运用了TTS,但部分编辑器例如CeVIO AI则是使用了DNN(deep neutral network,深层神经网络)或者CNN(convolution neutral network,卷积神经网络)的方法。简单而言,该系统使用计算机根据录制的声音创建「歌手个性」的模型,来让模型的歌唱更贴近真人。而像VOCALOID并没有使用DNN或是CNN这样的统计模型,只是采用了将各处的发音对应的波形连接的波形连接型声音合成(即传统的拼接声库)。不过值得一提的是,V6已经搭载了DNN学习功能,意味着我们也能在VOCALOID中使用AI声库了。
这两项技术并没有高低之分。你也许会使用DNN来追求极致的人声还原,使用自己喜爱的歌姬来还原真人歌唱的感觉,但例如“初音未来的消失”这样的曲子则不能通过DNN的形式来完成歌唱。传统的TTS形式可以完成更加灵活多变的演唱需求。
使用的宿主从来没有高低之分,百花齐放是最好的
尝试使用虚拟歌姬来进行创作
VOCALOID的入门使用
VOCALOID的界面比下列的编辑器界面较为复杂多样一些,不过VOCALOID非常贴心详细地准备了VOCALOID的用户入门手册,我们只需要通过阅读该手册就可以很好的入门VOCALOID编辑器。用户入门手册可以在VOCALOID官网就可以查询,因此我在下文只进行一些必要的名词解释。

VOCALOID的参数设计拥有更多细致化的操作。
值得一提的是,我们可以在VOCALOID v6及以上的版本中选择不同的歌声合成方式。
- 支持AI的声库可以编辑添加歌唱轨道,选择VOCALOID AI来使用运用了DNN技术来辅助创作者进行创作。
- 普通的声库则只需要选择VOCALOID的选项来进行创作(只有TTS技术的运用)
再次提及,使用DNN技术与否并不代表某个声库是否更加优越(即使我们经常在日常提及时作为一个梗而出现),不同的技术带来的听感是完全不同的,创作者只需要选择最适合自己的,或者最能表现自己歌曲或歌姬本身的特色即可。
VOCALOID的名词解释
- VEL(velocity 速度)
影响歌词当中辅音发声的时间长短。该数值越大,则辅音发声越短。 - DYN(dynamics 动态)
影响歌词当中的发声力度,情感。该数值越大,则歌唱时表现力,力量感越强。 - BRE(breathiness 气息声)
影响歌词当中的气息声,类比嘶哑度(husky)。
**注:气息声并不是换气声,歌姬的换气音(in & out)需要通过歌姬的呼吸音文件夹当中选择,在后期进行编辑。 - BRI(brightness 明亮度)
影响歌词当中的明亮度。该数值越大则声音越明亮,越小则越柔和。 - CLE(clearness 清晰度)
影响歌词当中的清晰度。该数值越大则表现越清晰,越小越模糊。
注:该参数并不是指我们传统意义上对于音质的清晰与模糊,而是对于音色上的调整。调整此参数也不能完全消除某些歌唱过程中的部分辅音过于模糊的情况,需要综合考虑切分歌词或者调整发声时间。 - OPE(opening 开口度)
影响歌词当中的发声饱满度。该数值影响歌词中的元音部分更加明显。 - GEN(gender 性别参数)
影响歌词当中的音色浑厚程度。该数值越大声音越偏男性,越小越偏女性。
注:如果想追求更加成熟或更加幼小的声音,请不要一昧地将该数值拉到过大或过小,而是应该考虑前期选择歌姬时的合理与否。 - POR(portamento timing 滑音调速)
影响歌词当中对于不同音高的音符的转换速度。该数值越大则音高的改变速度越慢,反之则越快。
举一个例子,例如提高该数值则更偏向在说唱效果中的快速音高下降效果;若降低该数值则是更偏向于某些发声的机器断电之后随着电量衰减而逐渐降低音高的效果。 - XSY(交叉合成)
影响多音色歌姬,声库当中的音色变化。尝试灵活更改参数来获得不同的歌唱效果。 - GWL(growl 咆哮效果)
影响歌唱当中模拟咆哮时的浑浊效果。 - PIT(pitch bend 音高变化)
影响歌词当中歌唱时的音高变化 - PBS(pitch bend sensibility 滑音敏感度)
影响pit的音高变化程度。pbs需要配合Ppit使用,该数值影响pit的变化速率,相同pit变化曲线下,pbs越大,则实际音高变化越大。(类似于颤音需要配合音高一同调整使用一样)
Synthesizer V的入门使用
我们需要先通过认证码进行认证,激活sv的编辑器界面声库
——歌声 一栏则选择加载你拥有的歌姬的声库模型。

选择歌姬完成之后,我们就可以开始进行创作了!
sv的编辑器导出方式有些特别,需要在右侧一栏中选择“渲染”,将你的作品进行导出
CeVIo的入门使用

这是正常使用界面,让我们从第一步开始

开始打开宿主之后,你会收到一个弹窗让你进行验证,输入你购买的编辑器的代码之后,接下来会让你继续输入你所购买的歌姬的代码。不购买歌姬单独购买编辑器是无法使用整个CeVIo软件的。输入代码之后,软件会自动下载声库,只需要等待下载即可。
简单讲讲对于CeVIo的编辑技巧
-
选择声库之后,一般会有对应音高,嘶哑(husky),音调(tune)和发声标准音高(pitch)
第一个音高对应的是影响歌姬的音色,提升以获得更浑厚成熟的声音,降低以获得更幼年尖细的声音。 -
部分歌姬,例如星界Sekai会多出一个选项——情感(Emotion),该参数用来调整歌姬在合成声音时的情绪。参数越高,则歌唱时发声,音高越不稳定。如有使用必要,则在提高适度情绪值时留意修改你的音符音高有无正确(按你认为的实际歌唱需要)进行发声,尤其对于音符中的音高(pit),颤音(vib),发声时间(tmg)进行修正。
-
在进行歌词的输入时,可以在假名的背后加注特殊符号来获得对应的歌唱效果:例如假声,颤音等一系列效果
(注:请确保输入特殊符号之前已切换英文键盘,否则编辑器将无法识别)
以下为部分CeVio歌姬的特殊符号效果,更多内容请查阅《CeVio用户手册》

Cevio目前支持特殊符号处理的歌姬一览

Voisona的入门使用
与以上编辑器不同的是,Voisona的本体使用并不需要购买,只需要在官网进行下载即可。在编辑器中有自带的声库——知声(Chis-A)

使用Voisona之前,只需要在官网进行账号注册,并在编辑器中绑定你的邮箱即可。
- 与其他编辑器不同的是,Voisona除了买断制之外还有订阅制,所以我们在Voisona网站购买声库时并没有序列码提供给你进行认证,而是在下载购买网站上(通常是DLsite)下载压缩包,打开其中的txt文件按指示进行操作。

- 在购买网站上和官网进行认证之后,你购买的声库会认证到你的账户上,此时打开你的编辑器,点击歌姬图标可选择你购买的歌姬进行下载。在歌姬一栏通常有多个历史版本进行选择,我们只需要下载最新版的就可以了。
值得一提的是,也许是因为CeVio和Voisona曾是同源的原因,我们依然能够使用CeVIo的特殊符号编辑功能来编辑Voisona当中的效果。
我们可以通过右键目标音符来选择特殊发声效果。
CeVio与Voisona的信息小结
在上文我们提到,cevio与voisona的制作公司是同一家, 因此cevio的文件(css)可以使用voisona打开,而voisona的文件(tssln)也可以使用cevio打开。
注意,如果使用的歌姬是同一个,歌手的歌唱特点无法与目标宿主保持一致,依然需要精调。
OpenUTAU的入门使用
OpenUTAU是一款本体和绝大部分声库完全免费的歌声合成软件,是由杉田朗主导、由UTAU社区为UTAU社区打造的免费开源歌声合成编辑器。简单的说,可以视为UTAU的升级版
OpenUTAU具备UTAU的所有功能及一些UTAU社区插件的功能,因此如果需要使用UTAU声库,编写者推荐直接使用OpenUTAU
可以在OpenUTAU官网获得软件下载地址,另附wiki,讨论组,详细教程等链接。OpenUTAU目前支持Windows,Mac,Linux,并即将支持Android
在官网获取适合自己系统的软件安装包并进行安装后,点开OpenUTAU,以Windows系统为例,如果看见这样的画面

恭喜,已经成功安装了OpenUTAU本体
但距离真正使用,还需要做一些其他的准备
安装歌手(声库)
只有安装了声库,OpenUTAU才能发声
最著名的重音Teto UTAU声库可以在TetoUTAU声库下载链接获取到(需要合适的网络环境)。如果打算使用Teto进行创作,推荐使用OpenUTAU用日本語統合ライブラリー。如果想要使用其他声库,前往那个声库的配布地址进行下载即可
所有的声库都可以直接将声库下载至桌面或任何位置并在安装后进行删除,OpenUTAU会自动在OpenUTAU的文件中留存一份
 、
、
注意OpenUTAU界面的左上角,点开当中的 工具 安装歌手...

在弹出的文件浏览器里选择刚才下载的声库文件(因网络问题此处编写者使用其他声库作为演示,重音Teto在内其他的所有声库同理)。选择正确的编码,使文件名看起来是正确可读的(这很重要!)。对于日文声库,一般选择Japanese(Shift-JIS)即可。在这之后点击下一步

下一步同理,选择正确的编码,使文件名看起来是正确可读的,随后安装即可
在此之后,如果能在 工具 歌手... 中找到刚才你所安装的声库,则安装成功

进行调声
点开界面上显示的 选择歌手 ,在弹出的界面中选择你需要使用的声库并鼠标左键单击轨道视窗以创造一条调声Part

鼠标左键双击粉色的调声Part以进入调声界面

基本操作
左键单点 → 创建一个音符 / 选中一个音符
右键对音符单点 → 音符功能菜单
右键点击空白处 → 取消选中
光标移动至音符头尾并左键长按 → 更改音符长度
左键双击 → 修改歌词
滚轮 → 调整可视的音高
Ctrl+左键长按拖拽 → 多选
空格 → 播放
OpenUTAU的表情及名词解释
选中一个音符,按Tab呼出/隐藏菜单,在右下角的位置即可看见“表情”选项
(注:以下的所有注释仅代表编写者调声时的个人理解,可能与实际功能或官方定义有所出入)
Voice Color:对于整合声库,可以在此处选择同一发音的不同感情/唱法
Resampler Engine:引擎混用的选项,无特殊需要则勿调整
Velocity:速度,可以理解为辅音与元音过渡的速度
Volume:音量
Attack:力量,越高的值则越有爆破音的感觉
Decay:渐弱
Gender:性别,可以调整声库的音色,类似共振峰
Breath:气音/气噪
Lowpass:低通滤波,高频随此数值的增加而削弱
Modulation:可以理解为自动调教
Alternate:调用替代采样,在单音采样出现问题时可以使用
Direct:开启此选项的音符完全不修改采样(包括音高,长度,所有属性)
Tone Shift:音高偏移
引擎
决定OpenUTAU调声效果的,除了声库和参数以外,最重要的就是“引擎”
不同的引擎会以不同的方式对采样进行渲染,同样的无参工程,仅仅更换引擎就可以让听感产生极大的变化。OpenUTAU自带WORLDLINE-R引擎和Classic引擎
引擎同声库一样可以安装,在此处仅简单说明OpenUTAU自带引擎之间的差别
Classic:支持所有表情,无参效果略差于WLR,需要更精细的调整,无参状态下渲染更有力量感,不支持部分声库的罗马音输入。建议在具有一定调教技术后使用
WLR:只支持部分表情,无参保证效果下限,但上限很低,适合新手微参使用,建议趁早进行更换,不要产生依赖
在看完这些基本介绍和操作教程之后,应该可以顺畅的使用OpenUTAU进行基础调声了
通用歌词编辑技巧
-
在输入歌词时,如歌词中的“を“ 无法很好地进行标准发音(通常会被误发成“o”音)”时,则可以使用“うぉ”来替代(编辑器会强化“wo”的发音强度)
-
当歌词中遇到连音,长音或强化辅音发音时无法正确表达时,可以试着调整时间(tmg),或者是音量(vol)值来进行处理;或者可以将原有的单词内加入い(i) う(u) お(o) ん(n)等尾音来强化连接音的效果,或用来平衡长音带来的发音偏移问题。歌词编辑时更多应注重发声的正确与否而不是歌词拼写的正确与否。
-
想让歌词中的音素只发辅音部分吗?在目标音符后添加“ ' ”即可(注意使用英文键盘),如果对效果不满意可以尝试直接在时间(tmg)中直接调节,延后元音的发音或直接去除元音的发音时间
-
“ん”的尾音鼻音过重?试试右键歌词中的音素选项,将“N”改为“n”(大小写区别),有时可以减轻过重的鼻音现象(尤其是低音)
-
想要模仿rap效果?试着编辑音高界面,将目标音高从上一个音符的音高或原有音符的音高开始,把音高拉低至原有音高的四度以下,并控制降低音高的起始位置要稍早于当前歌词发声的结束时间。
-
要想让歌姬有循序渐进的歌唱效果?试着将歌唱开头的发音音高降低三度,并略微晚些将音高恢复至原有音高(左低右高型波浪线)。
-
让歌姬更加接近真实人声的方法?试试可以通过自己亲自演唱,录音并找寻自己发声时的特点,为歌姬的发声时间和音高进行更加合理的修改。试着改变吸气与呼气时间(尤其是采用使用了DNN的声库时)。歌唱时的尾音,以及高音部分可以通过音高(pit)界面自行绘制波浪线以获得颤音效果,或直接通过颤音(vib)界面进行更直接的调整来获取人歌唱时所体现的“不稳定感”。刻意创造适当的瑕疵也是体现人类的歌唱的一种方式。